5.7 KiB
5.7 KiB
软件安全实现
一、安全编码原则
了解验证输入、避免缓冲区溢出、程序内部安全安全调用组件、禁用有风险的函数等通用安全编程准则;
了解相关的安全编码标准及建议;
理解常见的代码安全问题及处置办法。二、代码安全编译
了解代码编译需要关注的安全因素。三、代码安全审核
理解代码审查的目的;
了解常见源代码静态分析工具及方法。
一、安全编码原则
1、验证输入
- 对所有输入数据进行检查、验证及过滤
- 应用软件的“数据防火墙”,避免恶意数据进入。
- 什么时候验证
- 最初接收数据时
- (第一次)使用数据时
- 常见输入源
- 命令行
- 参数数量、数据格式、内容
- 环境变量
- 环境变量可能超出期望
- 有的环境变量存储格式存在危险
- 文件
- 不信任可以被不可信用户控制的文件内容
- 不信任临时文件
- 网络
- 来自网络的数据是“高度不可信的“
- 其他来源
- 命令行
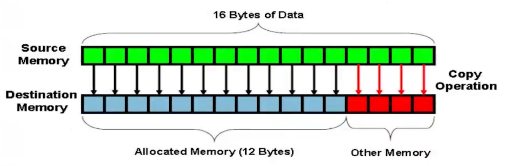
2、避免缓冲区溢出
-
缓冲区溢出
- 缓冲区:包含相同数据类型的实例的一个连续计算机内存块
- 溢出:数据被添加到分配给该缓冲区的内存块之外
-
外部数据比目标空间大
-
是一个非常普遍而且严重的问题
-
溢出后果
- 攻击者可以使远程服务程序或者本地程序崩溃
- 攻击者可以设计溢出后执行的代码
-
C/C++语言
- 语言特性决定
- 大量的库函数存在溢出
strcpy、strcat、gets等
-
其他语言
- 调用C语言库
- C#允许设置“不安全”例程
-
解决办法
- 填充数据时计算边界
- 动态分配内存
- 控制输入
- 使用没有缓冲区溢出问题的函数
strncpy、strncat、C++中std:string
- 使用替代库
Libmib、libsafe
- 基于探测方法的防御
StackGuard、ProPolice、/GS- 将一个“探测”值插入到返回地址的前面
- 非执行的堆栈防御
- 不可在堆栈上执行代码
- 填充数据时计算边界
3、程序内部安全
- 程序内部接口安全
- 程序内部接口数据的检查。
- 异常的安全处理
- 检测异常,安全处理各种可能运行路径;
- 检测到某些错误行为/数据,必须以合适的方式处理,保证程序运行安全;
- 必要时立即拒绝服务,.甚至不回送详细的错误代码。
- 最小化反馈
- 避免给予不可靠用户过多的信息
- 成功或失败
- 作为跟踪检查的日志可以记录较为详细的信息
- 认证程序在认证前尽量少给信息
- 如果程序接受了密码,不要返回它
- 避免给予不可靠用户过多的信息
- 避免竞争条件
- 访问共享资源时(文件/变量)没有被适当地控制
- 使用原子操作
- 使用锁操作避免死锁
- 安全使用临时文件
4、安全调用组件
-
应用程序实际上几乎都不会是自包含的,它们通常都会调用其他组件
-
底层的操作系统
-
数据库
-
可重用的库
-
网络服务(WEB、DNS)
-
-
使用安全组件,并且只采用安全的方式
-
检查组件文档,搜索相关说明
- gets
- 随机数
-
使用经过认可的组件
-
尽可能不调用外部命令,如果不得已要调用,必须严格检查参数
system、open、exec
-
-
正确处理返回值
- 一定要检查返回值调用是否成功
- 成功时检查
- 返回值,是否按照期望值处理
- 数据中可能含有NULL字符、无效字符或其他可能产生问题的东西
- 错误时检查
- 错误码
-
保护应用程序和组件之间传递的数据
- 视安全需求和安全环境
- 考虑传输加密,包括密码算法和安全协议
- 视安全需求和安全环境
5、禁用不安全函数
-
编码中禁止使用的危险函数举例

二、软件安全编译
1、确保编译环境的安全
- 使用最新版本编译器与支持工具
- 可靠的编译工具
- 使用编译器内置防御特性
2、确保运行环境的安全
- 将软件运行环境基于较新版本的系统
三、代码安全审核
1、什么是源代码审核
- 通过分析或检查源程序的语法、结构、过程、接口等来检查程序的正确性,报告源代码中可能隐藏的错误和缺陷。
2、源代码审核方式
- 人工审核
- 费时费力
- 容易遗漏
- 工具审核
- 速度快自动
- 可升级知识库
统计证明,在整个软件开发生命周期中,30%至70%的代码逻辑设计和编码缺陷是可以通过源代码审核来发现的。
在软件编码完成后,理想的做法是使用源代码审核工具审核和人工审核结合的方式对代码进行审核,能极大地减少软件中的安全问题被带人随后的软件生命周期阶段的可能性。